Building Raft Consensus from Scratch: Leader Election

I was curious about distributed consensus, and I figured that the best way to really understand it was to build something myself. I asked myself questions like: Why does each rule exist? What would happen if we took one away? This exploration led me to implement leader election in Go.
The full source code is available on GitHub. I highly recommend cloning it and setting up a 3-node cluster on your local machine as you go through the rest of the article.
The Dilemma: Agreeing Without a Referee
Picture this: you and four friends are trying to decide where to go for dinner in a group chat. Everyone needs to agree on one restaurant, but it’s not as simple as it sounds. Sometimes, phones unexpectedly die or messages take a while to come through. And what about those moments when two friends suggest different places at the same time?
If everyone just shouts out their suggestions whenever they feel like it, a few things can go awry:
1. You end up with multiple choices and no clear front-runner.
2. It takes ages to sort it all out.
3. The group ends up splitting up, and some friends go to Place A while others head to Place B.
That last scenario is a big deal! In the world of distributed systems, it’s known as "split-brain" and it's definitely not fun when two parts of the group make conflicting decisions. It’s all about finding a way to make sure everyone is on the same page.
A leader sidesteps all three problems. One person decides, tells everyone, done.
The clever insight at the heart of Raft is this:
Turn the hard problem (agreeing on every operation) into an easier problem (agreeing on a leader, then trusting the leader).
What If the Leader Dies?
Easy when the leader is alive. But what happens when the “decider” goes silent? Someone has to become the new leader without a higher authority telling them to.
Now we have new problems:
How does anyone notice the leader is gone?
How do we avoid two people declaring “I’m the new leader!” at the same time?
What if the old leader comes back online? What should happen?
Let me work through how I reasoned about each.
Problem 1: Detecting the leader is gone
The leader sends regular “I’m alive” messages(heartbeats). If a follower hasn’t heard one in a while, it assumes the leader is dead and decides it’s time to elect a new one.
That “while” is called the election timeout.
Problem 2: Two candidates declaring at once
Here’s where it gets interesting. If two followers’ timers expire simultaneously, they both become candidates and ask everyone for votes. The cluster splits its votes. Nobody wins. The election fails.
So how do we make this collision unlikely?
Each node picks a random election timeout - say, somewhere between 150ms and 300ms. Node A might wait 173ms, B waits 241ms, C waits 198ms. Whoever’s timer fires first becomes a candidate first, asks for votes first, and usually wins before anyone else even wakes up.
Why a range and not fixed, unique timeouts? Because if two nodes had fixed timeouts and a collision happened anyway (network delay, partition healing), they’d retry with the same fixed timeout and collide again. Forever. This is called a livelock. The system is “alive” but making no progress, which is worse than a crash because crashes are obvious.
Randomness breaks symmetry. There’s no central authority to say “you go first,” so we use randomness to make sure that, statistically, somebody goes first.
Why not 150–155ms instead of 150–300ms? A range that narrow is essentially a fixed timeout. Collisions become likely again. Wider range = more reliable elections, but slower failover when the leader actually dies. That’s the tradeoff.
Problem 3: The returning ghost leader
The old leader comes back online after a network blip. From his perspective, he was just briefly offline, and he might still think he’s in charge and start giving orders. Now we have two leaders.
The solution is a monotonic counter called the term. Every time an election starts, the term goes up: term 1, term 2, term 3...
The rule:
Every message includes the sender’s term. If you ever see a term higher than yours, you immediately step down to Follower and update your term.
So when the ghost leader sends his first stale heartbeat, the response carries a higher term, and he instantly demotes himself.
Problem 4: Double voting
What stops a follower from voting “yes” to multiple candidates in the same election? Nothing unless we add a rule:
Each node casts at most one vote per term, first-come-first-served.
Once a follower votes for A in term 5, it remembers and refuses everyone else until term 6. This prevents the disaster of two candidates both thinking they got a majority.
The Three Roles
Every node is always in exactly one of three states:
Follower : listening for heartbeats, voting when asked
Candidate : running for election
Leader : sending heartbeats, in charge
And the transitions:
Follower --(timeout, no heartbeat)--> Candidate
Candidate --(majority votes)--> Leader
Candidate --(saw higher term)--> Follower
Leader --(saw higher term)--> Follower
A Note on Randomness (Raft vs Web3)
Is this the same kind of randomness used in blockchain systems?
Same philosophy, very different strength. Both answer the question “who goes first when nobody is in charge?” But:
Raft uses cheap randomness (
rand.Intn) because nobody is attacking it. It’s just breaking ties between friendly peers.Web3 uses cryptographic randomness (VRFs, RANDAO) because adversaries actively try to predict and exploit it.
If a Raft random number is predicted, nothing bad happens. If a Web3 one is, money gets stolen.
The Implementation
I built this in Go because Go’s goroutines and channels map naturally to how Raft thinks. Each node is a tiny independent state machine that occasionally talks to others.
For networking, I picked the standard library (net/http with JSON) over a P2P framework like libp2p because it only needs a fixed list of peers and two simple RPCs. Using a heavyweight framework would hide the very mechanics I was trying to learn.
Project structure
raft/
├── main.go // entry point: parse flags, start a node
├── node.go // the Node struct & state machine logic
├── rpc.go // HTTP handlers + RPC client calls
└── types.go // request/response structs
The two RPCs
Just two messages exist between nodes, each as a request/response pair:
// types.go
type RequestVoteArgs struct {
Term int `json:"term"`
CandidateID string `json:"candidateId"`
}
type RequestVoteReply struct {
Term int `json:"term"`
VoteGranted bool `json:"voteGranted"`
}
type AppendEntriesArgs struct {
Term int `json:"term"`
LeaderID string `json:"leaderId"`
}
type AppendEntriesReply struct {
Term int `json:"term"`
Success bool `json:"success"`
}
Notice that every message, request, and response carries a term. This is what makes the “higher term wins” rule work in both directions. A response of “no, I won’t vote for you, and by the way my term is 8” instantly tells a stale candidate it’s behind.
AppendEntries : It is named generically because, in a complete Raft implementation, it carries log entries too. For leader-election, it’s just a heartbeat.
The Node struct
All states in one struct, guarded by one mutex. The fields are tightly coupled, you almost always read or write several together, so splitting them across multiple structs would create more problems than it solves.
// node.go
type Role int
const (
Follower Role = iota
Candidate
Leader
)
type Node struct {
mu sync.Mutex
// Identity & config (set at startup, never change)
id string
peers []string
// Persistent state (would survive a restart if we wrote to disk)
currentTerm int
votedFor string
// Volatile state
role Role
leaderID string
// Timing
lastHeartbeat time.Time
}
The main loop
The node runs forever, dispatching to a different function based on its current role:
func (n *Node) Run() {
for {
n.mu.Lock()
role := n.role
n.mu.Unlock()
switch role {
case Follower:
n.runFollower()
case Candidate:
n.runCandidate()
case Leader:
n.runLeader()
}
}
}
Follower behavior
Sleep until the election timeout. If no heartbeat arrived during the sleep, become a candidate.
func (n *Node) runFollower() {
timeout := randomElectionTimeout()
time.Sleep(timeout)
n.mu.Lock()
defer n.mu.Unlock()
if time.Since(n.lastHeartbeat) >= timeout {
log.Printf("[%s] follower timed out, becoming candidate", n.id)
n.role = Candidate
}
}
Candidate behavior: the heart of leader election
A candidate increments the term, votes for itself, then asks every peer for a vote in parallel:
func (n *Node) runCandidate() {
n.mu.Lock()
n.currentTerm++
n.votedFor = n.id
term := n.currentTerm
n.lastHeartbeat = time.Now()
n.mu.Unlock()
votes := 1 // we voted for ourselves
var votesMu sync.Mutex
var wg sync.WaitGroup
for _, peer := range n.peers {
wg.Add(1)
go func(peer string) {
defer wg.Done()
args := RequestVoteArgs{Term: term, CandidateID: n.id}
var reply RequestVoteReply
if err := sendRequestVote(peer, args, &reply); err != nil {
return
}
n.mu.Lock()
defer n.mu.Unlock()
// Higher term in reply? Step down.
if reply.Term > n.currentTerm {
n.currentTerm = reply.Term
n.votedFor = ""
n.role = Follower
return
}
if reply.Term != term || n.role != Candidate {
return // stale reply
}
if reply.VoteGranted {
votesMu.Lock()
votes++
count := votes
votesMu.Unlock()
if count > (len(n.peers)+1)/2 {
n.role = Leader
n.leaderID = n.id
}
}
}(peer)
}
// ... wait for either all replies or election timeout
}
Three rules in this code, each maps to a concept we derived:
Saw a higher term in any reply → step down. That’s the ghost-leader defense.
Stale reply (term doesn’t match) → ignore. Networks are slow; old replies arrive in new elections.
Got majority
(len(peers)+1)/2 + 1→ become a leader. A strict majority is what makes Raft safe even with crashes.
Leader behavior
Send heartbeats to all peers periodically, on an interval much shorter than the election timeout:
func (n *Node) runLeader() {
n.mu.Lock()
term := n.currentTerm
n.mu.Unlock()
for _, peer := range n.peers {
go func(peer string) {
args := AppendEntriesArgs{Term: term, LeaderID: n.id}
var reply AppendEntriesReply
if err := sendAppendEntries(peer, args, &reply); err != nil {
return
}
n.mu.Lock()
defer n.mu.Unlock()
if reply.Term > n.currentTerm {
n.currentTerm = reply.Term
n.votedFor = ""
n.role = Follower
n.leaderID = ""
}
}(peer)
}
time.Sleep(heartbeatInterval)
}
The heartbeat interval must be much shorter than the election timeout. Otherwise, followers will time out between heartbeats and start unnecessary elections.
Handling incoming requests
When a vote request arrives:
func (n *Node) HandleRequestVote(args RequestVoteArgs) RequestVoteReply {
n.mu.Lock()
defer n.mu.Unlock()
reply := RequestVoteReply{Term: n.currentTerm, VoteGranted: false}
if args.Term < n.currentTerm {
return reply // stale candidate, reject
}
if args.Term > n.currentTerm {
n.currentTerm = args.Term
n.votedFor = ""
n.role = Follower
n.leaderID = ""
reply.Term = args.Term
}
// Vote if we haven't voted, OR we already voted for this same candidate
if n.votedFor == "" || n.votedFor == args.CandidateID {
n.votedFor = args.CandidateID
reply.VoteGranted = true
n.lastHeartbeat = time.Now()
}
return reply
}
Notice the one-vote-per-term rule on the last if: only grant the vote if we haven’t voted yet, or if it’s the same candidate re-asking (which is safe, it’s not a double vote).
When a heartbeat arrives:
func (n *Node) HandleAppendEntries(args AppendEntriesArgs) AppendEntriesReply {
n.mu.Lock()
defer n.mu.Unlock()
reply := AppendEntriesReply{Term: n.currentTerm, Success: false}
if args.Term < n.currentTerm {
return reply // stale leader, reject
}
if args.Term > n.currentTerm {
n.currentTerm = args.Term
n.votedFor = ""
reply.Term = args.Term
}
n.role = Follower
n.leaderID = args.LeaderID
n.lastHeartbeat = time.Now()
reply.Success = true
return reply
}
A valid heartbeat resets lastHeartbeat, which prevents the follower’s timer from firing.
The HTTP wiring
Bookkeeping. Each node runs an HTTP server with two endpoints:
// rpc.go
func (n *Node) StartServer(port string) error {
mux := http.NewServeMux()
mux.HandleFunc("/request-vote", func(w http.ResponseWriter, r *http.Request) {
var args RequestVoteArgs
json.NewDecoder(r.Body).Decode(&args)
json.NewEncoder(w).Encode(n.HandleRequestVote(args))
})
mux.HandleFunc("/append-entries", func(w http.ResponseWriter, r *http.Request) {
var args AppendEntriesArgs
json.NewDecoder(r.Body).Decode(&args)
json.NewEncoder(w).Encode(n.HandleAppendEntries(args))
})
return http.ListenAndServe(":"+port, mux)
}
A bonus of using HTTP/JSON: you can debug your cluster with curl. Want to manually send a vote request to see how a node responds? You can.
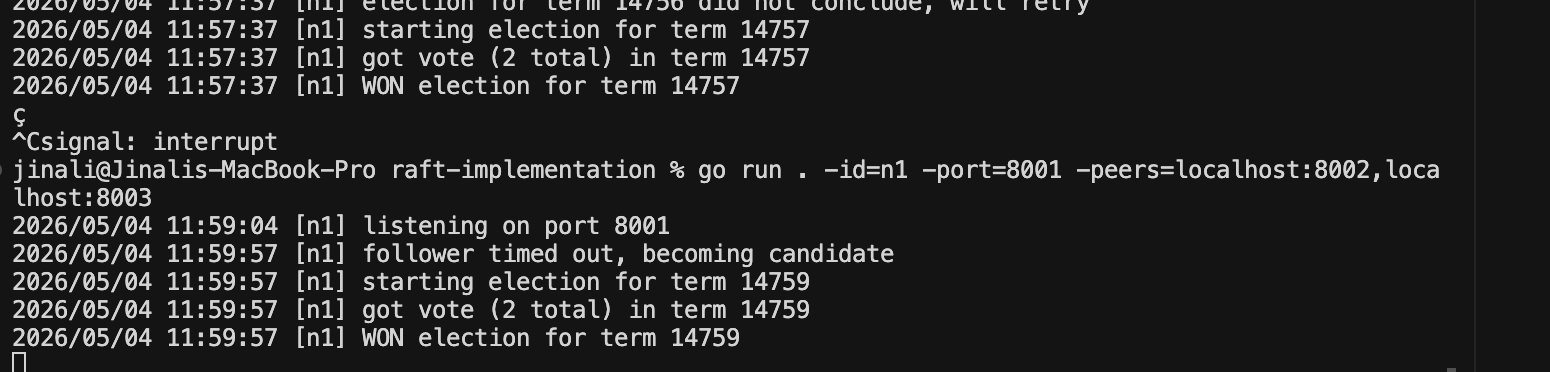
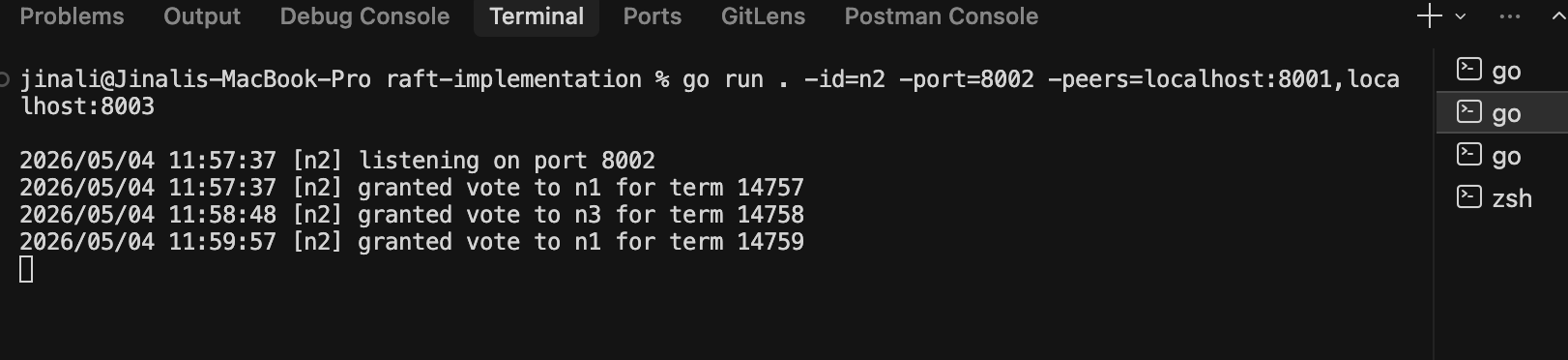
Running It
go mod init raft
# Three terminals:
go run . -id=n1 -port=8001 -peers=localhost:8002,localhost:8003
go run . -id=n2 -port=8002 -peers=localhost:8001,localhost:8003
go run . -id=n3 -port=8003 -peers=localhost:8001,localhost:8002
Within seconds, one node logs WON election for term N and starts heartbeating. Kill that node, and within another few seconds, a new leader emerges in a higher term. Restart the dead one, it joins as a follower in the new term.
What I Built vs What Real Raft Does
What’s here is Layer 1: Leader Election only. Real Raft has more layers:
Log replication : the leader actually accepts commands and replicates them to followers, so they all execute the same ordered sequence of operations.
Persistence : writing
currentTerm,votedFor, and the log to disk so a node can survive a crash without violating safety.Snapshots / log compaction : logs grow forever otherwise.
Cluster membership changes : adding and removing nodes safely.
What I Took Away
The most surprising thing about Raft isn’t how it works but it’s how little there is to it. Three states. Two RPCs. Six rules. And from those six rules, every safety property falls out naturally:
Randomized timeouts prevent livelock
Monotonic terms prevent stale leaders
One vote per term prevents split decisions
Strict majority prevents split brain
“Higher term wins” in every message keeps everyone in sync
Other consensus algorithms often have many complex components. Raft simplifies this by eliminating anything that isn't strictly necessary, resulting in a model that is small enough for one person to fully understand.
I believe this highlights an important lesson in distributed systems: simplicity is not merely about aesthetics. Instead, simplicity is a means to achieve correctness that can be easily verified.
Reference
In Search of an Understandable Consensus Algorithm (Ongaro & Ousterhout) - the original Raft paper
The Raft Visualization - an interactive diagram of the algorithm